Teaching with AI
When I tell people (especially academics) that I research AI, they often ask about classroom uses of AI. The questions are anxious ones. Will students lose access to reliable information? Will they forget how to write? Can teachers retain control over pedagogy? Will teaching jobs disappear? When it comes to the present state of LLMs in the classroom, there’s much reason for concern and so many unknowns. We need more experiments to explore their possibilities and pitfalls.
Lisa Messeri, with whom I taught Technology and Culture at Yale, did one such experiment. She offered students a relatively open policy on the use of AI to aid with assignments, and she even used ChatGPT to design an experimental lesson plan. She lays out her findings in a recent Anthropology Now article. As she reports, students using tools like ChatGPT as research assistants are exposed to fabricated yet convincing facts. Similarly, students using AI as a brainstorming aid risk stunting their creative thinking. Attuned to reality of college campuses today, however, Messeri concludes that “there might be little we can do to curtail students’ instincts to incorporate AI into their workflow.” So what is there to do?
Part of the present issues might stem from the preference for all-purpose chat models like ChatGPT. These models are certainly impressive, and they score highly on even the most advanced standardized test questions. But the questions used to evaluate these models are typically more narrow than the open-ended questions students face in fields from anthropology and to computer science.[1] These open-ended contexts are precisely where the models struggle in the ways Messeri outlines above. Trained on incomprehensibly large datasets, generalist models are not equipped with a particular field’s specialized know-how for working with information. Their one-size-fits-all approach often falls short of the particular needs of a single field of expertise.
What if we turned to more specialized AI models? In turn, what if these more specialized models were equipped with a structured, curated, and factually grounded context for answering queries? To explore this possibility, I experimented with retrieval-augmented generation (RAG), a technique currently embraced in business applications for its purported accuracy and reliability. The result of this experiment is “AnthropoloGPT”: a text generation model designed to answer questions about anthropology using only information contained in the Open Encyclopedia of Anthropology.
In this post, I describe the model in its current form and reflect on its performance.
Model Overview:
AnthropoloGPT employs retrieval-augmented generation, or RAG. This means that it uses a pre-built knowledge base. When generating a response to user queries, the model constructs a context from this knowledge base and consults that context for information. Ideally, this context provides all the factual information the LLM needs, and it does not need to draw facts from its pre-training and fine-tuning datasets. This is an important distinction because the context window provides traceable information whereas the training datasets do not. When a RAG system works as planned, users have far greater control and knowledge of the information they receive from the model. And as I show here, a RAG system can even cite its source documents in a verifiable way.
AnthropoloGPT’s design is based on the example provided by this helpful HuggingFace cookbook, which provides code that I adapted for the task at hand. GitHub’s Copilot also deserves some credit for help customizing the model.
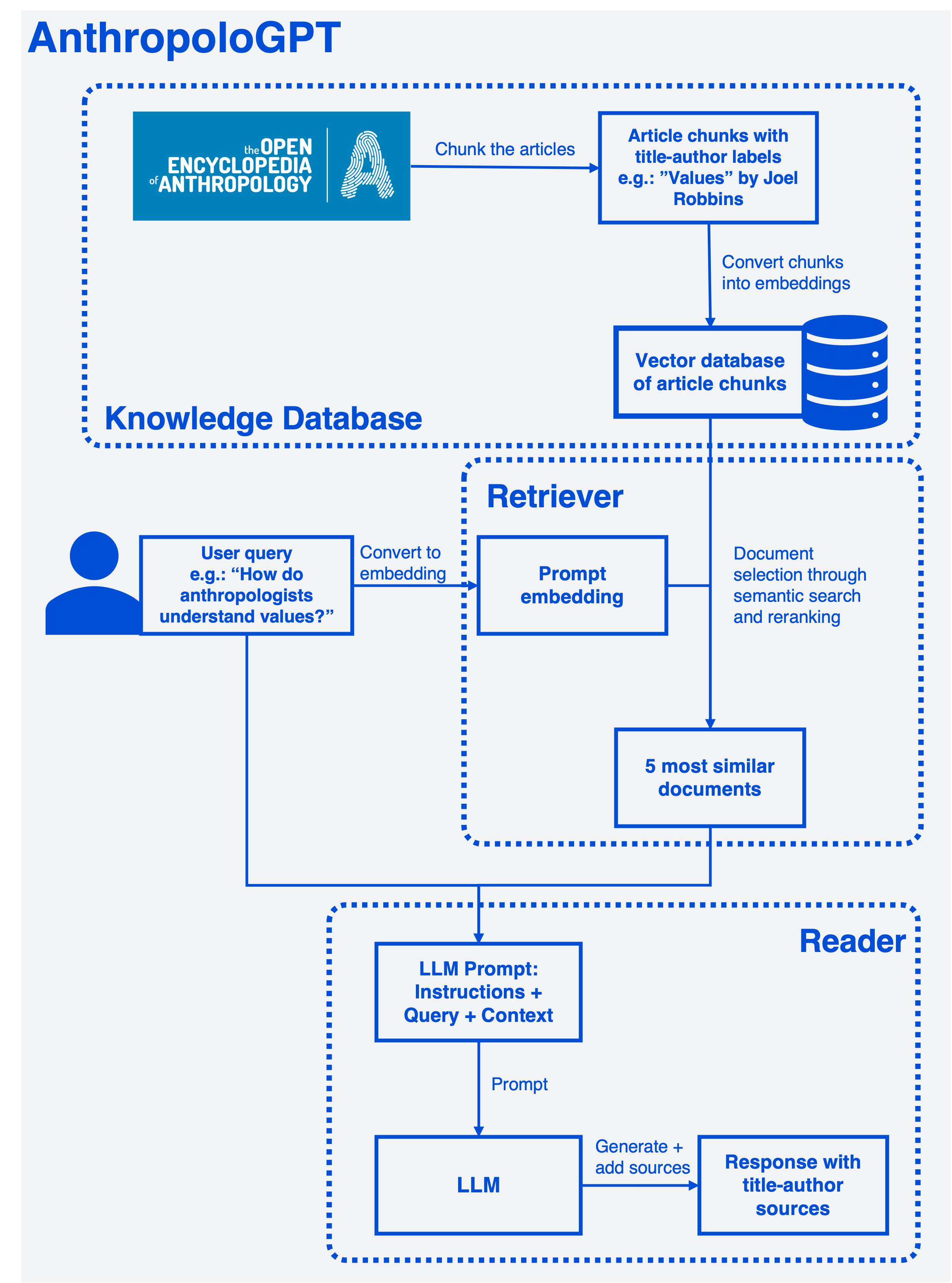
I first built a knowledge base of documents—in this case, the Open Encyclopedia of Anthropology, which I upload into the system as a series of text files. Since each article is too long for use in a single context window, the articles are first chunked into smaller pieces. Chunks largely align with each article’s constituent sections and paragraphs, which serve as proxies of individual semantic units. To prevent the collected chunks from exceeding the size allowed by the context window, individual chunk size is limited to 300 tokens. The resulting chunks serve as the final documents from which the model can draw after receiving a query. During the chunking process, the final documents retain the original title and author as metadata. This metadata can be pulled through the following steps without funneling them through the text generator’s nondeterministic algorithms, which might scramble it.
The model searches for the documents that are most semantically similar to the user-provided prompt. To accomplish this, the documents are converted into a database of vector representations called embeddings. The prompt is converted into an embedding using the same method. Represented as vectors, the prompt and documents can be compared by measuring their distance in the multi-dimensional embedding space, with proximity indicating semantic similarity. The goal is to select the five most similar documents. To improve accuracy, the model initially pulls more than 5 relevant results and re-ranks them before selecting the final 5, which are stored for generation. The documents’ title-author information is stored as a separate list.
The prompt and context are then entered into the model along with instructions for answering the prompt using information from the context. After some trial and error, I selected the following prompt template:
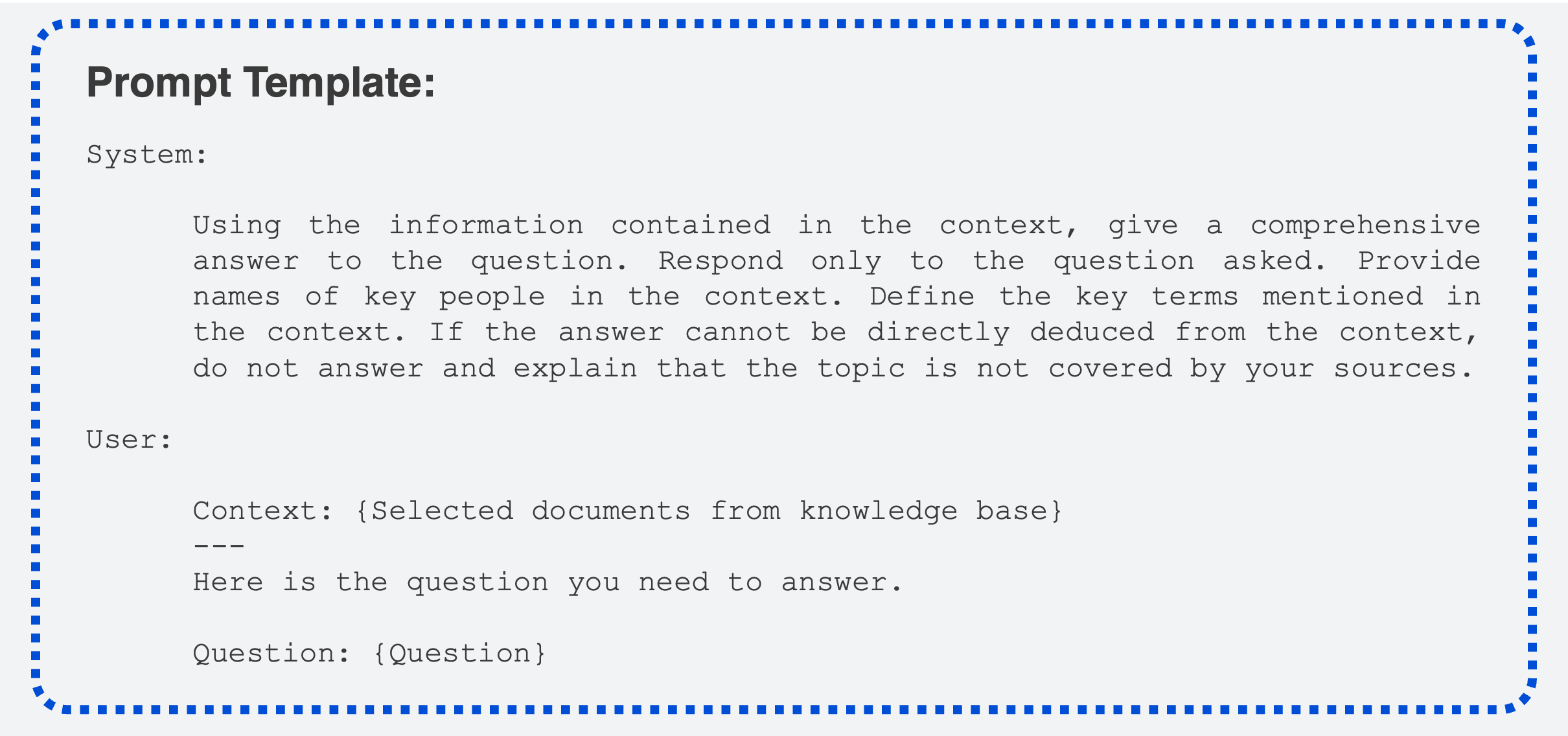
As you can see here, the system prompt encourages the model to stick to the task at hand and refrain from answering questions beyond the scope of the knowledge base. These are two key requirements for any RAG application. For the specific application at hand, the system prompt also encourages the model to include relevant definitions and figures contained within the documents.
Based on the constructed prompt, the model generates a response. Once generated, the relevant documents’ title and author information is then added to the response string. The final output answers the user’s question based on the provided context and cites its sources from the Encyclopedia.
Model Evaluation
Evaluation Approach
To explore the results, I generated responses to 25 prompts and assess them by hand. I do not “grade” the responses; instead, I search for interesting features that offer a sense of the method’s overall possibilities and limits.[2] I selected the evaluation prompts based on my knowledge of anthropology. Since model only performs correctly when relevant information is contained in the knowledge base, I also selected prompts that could be reasonably answered with sources from the Open Encyclopedia. It is important to note that while the Encyclopedia aims for broad coverage of the field, it remains a work in progress, and some subfields are better represented than others at the present moment. To test the model’s limits, I added prompts covering topics outside of anthropology (e.g. “What is string theory?”), hoping that the model will refrain from responding to them. The list of evaluation prompts is linked below.
Results at a Glance
Example prompts about magic and kinship, two classic anthro topics, give a sense of how the model responds.


Considering the model’s current state as a bare-bones proof of concept, the overall responses are generally impressive. But as far as following the criteria requested in the prompt, some are much better than others. Of the two illustrated here, the magic response is better. It offers a well explained overview of magic that highlights the important point that anthropologists study magic on the terms of the people who practice it. It includes the last names of relevant people found in the article it consulted. There are more names that could’ve been included, and first names would help, but it’s a good start!
The kinship response is also impressive upon first glance—it explains the main approach to kinship and even cites Durkheim, a key theorist in anthropology’s history. There’s a critical error here, however: the Durkheim quote is miswritten. According to the source material (“Adoption” by Jessaca Leinaweaver), Durkheim wrote that kinship “is a social bond or it is nothing,” not that it is “social or nothing.” The versions are close and similar enough in meaning, but when it comes to quotations, only an exact match is acceptable. Dropping the quotes to paraphrase Durkheim would’ve been fine, but that’s not what the model does here. There’s still more work needed to get this right, though nondeterministic text generation alone may not be capable of reliably quoting text when summarizing a document.
Further Discussion and Conclusion
1. The model introduces anthropology pretty well
When relevant reference data exists in the knowledge base, the resulting output is generally helpful and focuses on anthropologists’ unique approach to theory and methodology. Because anthropologists study all aspects of human experience, everything they study can also be studied by researchers in other fields, and I’m often asked how anthropological research is different from other social sciences. The responses here explain that difference well. Here’s what the model says about the study of economics, for example:
Anthropologists approach economics from a different perspective than traditional economists. While economists typically focus on how individuals and markets respond to incentives, costs, and markets, anthropologists examine the social and cultural meanings and relationships surrounding economic activities, particularly in non-Western, pre-industrial societies[…]
2. A limited knowledge base limits overall performance, but the model has some sense of boundaries
Unsurprisingly, the best responses are typically those with the most directly related sources—ideally an article about the same topic. A few of the disappointing responses had few or no intuitively relevant articles in the Encyclopedia. In those cases, the model responded with some irrelevant and distracting details. A RAG system will only be as good as its knowledge base, so any application must be guided by deep familiarity of the source material.
However, the model could grasp the limits of the knowledge base. When I asked about topics that were clearly beyond the scope—topics like string theory and large language models—the model correctly withheld a response. An open question is how to make it’s sense of limits more conservative.
3. Factuality remains an issue
Overall, the model did a pretty good job of transferring the factual data from the source material, but it did not perform perfectly. The Durkheim misquotation featured above illustrates this. Here’s another example from a response about property:
[…]anthropologist Karl Polanyi described land as a “fictitious commodity” in pre-capitalist societies, as it could not typically be sold and purchased[…]
This is incorrect. Fictitious commodities, like all commodities, only exist in capitalist societies. To say that any fictitious commodity exists in pre-capitalist societies simply makes no sense. Thanks to the system’s citational features, I tracked the Polanyi reference to its original Encyclopedia source:
The economic historian Karl Polanyi (1944) described land as a ‘fictitious commodity’, showing – as economic anthropologists have later done – that in pre-capitalist societies it could usually not be sold and purchased. (“Climate Change” by Thomas Hylland Eriksen)
Clearly, the model fumbled some of the statement’s internal logic when summarizing, which can cause confusion, if not misinform users. This experiment uses a relatively smaller model than the current state-of-the-art, and today’s most capable models may summarize more reliably. Nonetheless, subtleties like this are important to get right, and doing so through current paradigms in generative AI is not yet assured, even with the added control offered by RAG.
4. The availability of precise and trustworthy sources is critical
Given LLM’s citational challenges, I was most interested in the ability to provide sources with full confidence in their truthfulness. In my view, this is the greatest potential of RAG because the sources can be carried to the final output without passing them through any nondeterministic algorithms. This feature empowers users to check the sources when in doubt. In this current version, the Encyclopedia sources are provided without comment, and there are admittedly some surprising ones. Perhaps in future versions, sources could be weighted to provide users with a better understanding of which contributed most to the final response.
5. This experiment is limited and there are already existing opportunities for improvement
Admittedly, the capabilities of this model are just as limited by my own technical skillset as they are by the technology’s current capabilities. I’m sure that some of the issues described here can be improved using solutions that already exist today. For one, a larger knowledge base would certainly make the model more robust. Restructuring the source data and altering the search method might also improve retrieval performance. Using a more powerful model might reduce the frequency of summarization errors. Finetuning the model might also improve the quality of its responses. That said, none of these steps alter the system’s fundamental architecture, so there’s no assurance that the problems surfaced here will be fully resolved.
Given the possibilities shown here, especially when it comes to the inclusion of ground truth sources with otherwise generated responses, I’m interested in pushing this further. As new approaches emerge in the field—and as my own technical skills improve—I hope to keep tinkering to see how changes like those suggested here can improve its performance.
Resources from the experiment:
If you’re interested in this experiment and want to check it out yourself or brainstorm ideas, please reach out! I also welcome all suggestions for technical improvements.
[1] Current paradigms in model evaluation necessitate the use of narrow questions so that models can be assessed at scale. This is a key challenge in the evaluation of generative models, which are often used in domains where humans’ evaluation criteria can be open-ended, dependent on context, and often in conflict across cases.
[2] For a model like this, it’s possible to automate evaluation using an LLM-as-judge to survey a far larger dataset of outputs, but since this experiment is exploratory in nature, such an approach might limit the kinds of insights it can surface.
